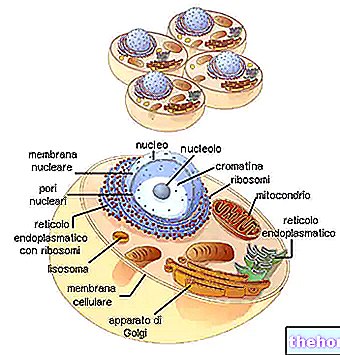
Aby existovala zhoda medzi informáciou o polynukleotide a informáciou o polypeptide, existuje kód: genetický kód.
Všeobecné charakteristiky genetického kódu je možné uviesť nasledovne:
Genetický kód sa skladá z trojčiat a neobsahuje vnútornú interpunkciu (Crick & Brenner,).
Rozlúštilo sa to pomocou „translačných systémov s otvorenými bunkami“ (Nirenberg & Matthaei, 1961; Nirenberg & Leder, 1964; Korana, 1964).
Je veľmi zdegenerovaný (synonymá).
Organizácia tabuľky kódov nie je náhodná.
Trojčatá „nezmysel“.
Genetický kód je „štandardný“, ale nie „univerzálny“.
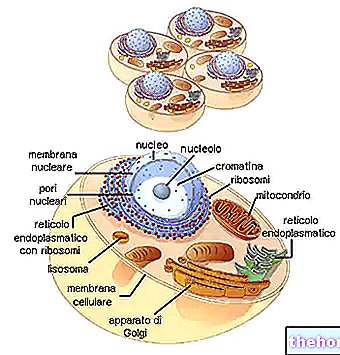
Pri pohľade na tabuľku genetického kódu je potrebné pripomenúť, že sa týka prekladu „RNAm k polypeptidu, pre ktorý sú príslušnými nukleotidovými bázami A, U, G, C. Biosyntéza polypeptidového reťazca je prekladom nukleotidovú sekvenciu v sekvencii aminokyseliny.

Každý triplet bázy RNAm, nazývaný kodón, má prvú bázu v ľavom stĺpci, druhú v hornom riadku a tretiu v pravom stĺpci. Vezmime si napríklad tryptofán (tj. Try) a vidíme, že zodpovedajúci kodón bude byť v poriadku UGG. V skutočnosti prvá základňa, U, obsahuje celý rad políčok v hornej časti; v tomto G identifikuje pole úplne vpravo a štvrtý riadok samotného poľa, kde nájdeme napísané Skúste. Podobne na syntézu tetrapeptidu Leucine-Alanine-Arginine-Serína (symboly Leu-Ala-Arg-Ser) môžeme v kóde nájsť kodóny UUA-AUC-AGA-UCA.

V tomto mieste však treba poznamenať, že všetky aminokyseliny nášho tetrapeptidu sú kódované (na rozdiel od tryptofánu) viac ako jedným kodónom. Nie je náhoda, že v práve uvedenom príklade sme vybrali uvedené kodóny.Mohli sme kódovať ten istý tripeptid s inou sekvenciou RNAm, ako napríklad CUC-GCC-CGG-UCC.
Skutočnosť, že jedna aminokyselina zodpovedala viac ako trojici, pôvodne dostala význam náhodnosti, vyjadrená aj vo výbere termínu degenerácie kódu, ktorý sa používa na definovanie javu synonymie. Na druhej strane niektoré údaje naznačujú, že dostupnosť synoným odkazujúcich na rôznu stabilitu genetickej informácie nie je vôbec náhodná. Zdá sa, že to potvrdzuje aj zistenie odlišnej hodnoty pomeru A + T / G + C v rôznych fázach evolúcie. Napríklad u prokaryotov, kde potreba variability nie je uspokojená pravidlami mendelizmu a neo-mendelizmu, má pomer A + T / G + C tendenciu sa zvyšovať. Následná nižšia stabilita, tvárou v tvár mutáciám, poskytuje väčšiu príležitosti pre variabilitu náhodnú z génovej mutácie.
V eukaryotoch, najmä v mnohobunkových bunkách, u ktorých je potrebné, aby bunky jedného organizmu držali rovnaké dedičné dedičstvo, má pomer A + T / G + C v DNA tendenciu klesať, čím sa znižuje možnosť somatických génových mutácií .
Existencia synonymných kodónov v genetickom kóde vyvoláva už spomínaný problém s multiplicitou alebo bez antikodónov v RNAt.
Je isté, že pre každú aminokyselinu existuje najmenej jedna RNAt, ale nie je rovnako isté, či sa jedna RNAt môže viazať na jeden kodón, alebo môže rozpoznať synonymá indiferentne (obzvlášť keď sa tieto líšia iba pre tretiu bázu).
Môžeme dospieť k záveru, že pre každú aminokyselinu existujú v priemere tri synonymné kodóny, zatiaľ čo antikodóny sú najmenej jeden a nie viac ako tri.
Pripomínajúc si, že gény sú určené ako jednotlivé úseky veľmi dlhých polynukleotidových sekvencií DNA, je zrejmé, že začiatok a koniec jedného génu musia byť nevyhnutne obsiahnuté v pamäti.
BIOSYNTÉZA PROTEÍNOV
V rôznych častiach DNA dochádza k otvoreniu dvojitého reťazca a syntéze rôznych typov RNA.
Počas kroku načítania sa RNAt viaže na aminokyseliny (predtým aktivované ATP a špecifickým enzýmom). Biosyntetický „stroj“ nie je schopný „opraviť“ nesprávne vložené tRNA.
RNAr sa potom rozdelí na dve podjednotky a väzbou na ribozomálne proteíny vedie k zostaveniu ribozómov.
RNAm, prechádzajúca cytoplazmou, sa viaže na ribozómy a tvorí polyzóm. Každý ribozóm, prúdiaci na posla, postupne hostí RNAt komplementárny k relatívnym kodónom, pričom odoberá aminokyseliny a pri tvorbe ich viaže na polypeptidový reťazec.
Relatívne stabilná RNAt sa znova dostáva do obehu. Ribozómy sa tiež znova použijú, čím sa uvoľní už zostavený polypeptid.
Posol, menej stabilný, pretože je jednokatenový, sa štiepi (ribonukleázou) na základné ribonukleotidy.
Cyklus teda pokračuje a syntetizuje jeden po druhom polypeptidy na messengerových RNA dodávaných transkripciou.